CI/CD Review - How DevOps in Real Life & Mature Organizations works
On this page
People love checklists because they give the illusion of an easy success. But DevOps is not straight-forward and looks different for each team and application. That is why I conduct reviews with Azure customers as an engineer at Microsoft in an interview-style discussion. And like an interview, I'm not challenging your answers, but your thought process.
Want some more context and answers? Watch me walkthrough some of these questions and share examples from real life.
Privacy Notice - if you play the embedded video, you acknowledge and agree to cookies set by YouTube.com
Goal of the Review
This exercise focuses on DevOps in practice, not in theory. After going through the questions, you should be able to better gauge your confidence in your practices meeting the requirements of your use case. It will also help you figure out what is the next practice you want to improve upon.
Most of us don't meet every requirement and do everything listed below all the time for every project. Re-visit this exercise every now and thing and continuously improve.
Keep in mind this conversation is cloud-agnostic and therefore for everyone, not just Microsoft Azure customers. In fact, if you know me personally you will know my favorite CI/CD tool is Jenkins.
The questions are organized into the following categories, loosely structured around Microsoft's Well Architected Framework:
Release Management
1. What is your versioning scheme?
- Can you tell me which versions of your code are on Dev vs QA vs Production?
- Consider Semantic Versioning format of
MAJOR.MINOR.PATCHis most common in Open Source Software.
2. Do you use naming conventions?
- Branch names
Common examples include:
feat/*fix/*mainproductionqa
- Commit messagesConventional Commits is a common standard in Open Source. Examples include:
docs(readme): add instructionschore(deps): updatechore(release): 0.7.0feat(signup): add new buttonfix(ui): misaligned header
3. Do you have a Change Log?
- Is it automated?
- It is absolutely OK to start with a manual change log.
This is an example changelog from my azure-nodejs-demo project, which is generated with Standard Version:

4. Are you linking commits to features, bugs, etc. in your dev planning tool (e.g. Azure Boards or GitHub Issues)?
Note how in the example change log above the features and bug fixes are linked to specific commits. It's easier than it looks. For more info, see your provider's documentation:
- GitHub: Autolinked references and URLs
- GitLab: Crosslinking Issues
- Azure DevOps: Link to work items from pull requests, commits, and comments
5. Can you describe your git branching workflow?
There is no single "correct" answer, even for the same use case. A developer team must decide together and commit to following it. One of the most frustrating periods in my career was trying to force my co-workers to work in the pedantic way I do. Unsurprisingly I was not very popular. We were working to port a legacy application to the cloud and eventually the team learned to appreciate git submodules, after they gained experience how. It was my mistake to not let them learn at their own pace.
Pro Tips
- Your branch workflow should be documented. Consider also drawing this out.
- To test your mastery, see if you can explain your workflow without notes and sketch the workflow from scratch. Start with a simple monolithic project, then do the same with more complex situations, e.g. with:
- dependencies on other services
- distinct environments, e.g.
staging,uatandproduction - infrastructure - if you own it and have infrastructure as code
Resources: Getting Started with Git Workflows
- This comparing workflows article from Atlassian is a good place to start.
- OneFlow is also popular, more recent and worth mentioning.
Pipelines
Please note these questions will be very workload specific. If you are trying to measure your own expertise, try mapping out answers for both simple and complex workloads.
6. Do your pipelines generate assets, e.g. binaries, builds?
- How are they archived?
- How are they distributed? How many people in your organization have access?
- Have you built artifacts that contain secrets or certificates? Have you secured them? Note: obviously you should not do this. But sometimes you have to deal with a legacy application.
7. When your pipeline runs, how many environments does it deploy to?
One push should trigger deployment(s) for a single environment. Confirm that you have used conditions and triggers properly to ensure production is not accidentally deployed to.
8. Do you schedule your pipelines to run regularly to ensure it still works?
- Are you just running unit tests?
- Are you also deploying to (non-prod) environments?
9. How do you re-use pipeline code?
If you are just starting with DevOps, ignore this. An additional abstraction layer will not help you master the one measure that matters: how often you deploy. If you choose to go this route, I would ask you:
- WHY? What do you hope to achieve?
- What is your versioning model?
- Is this a public or private library? If private, how to you secure it?
- Who owns and maintains this code?
If you want to pursue knowledge transfer in your organization, I can tell you based on first hand experience at Allianz Germany, this is more daunting than it appears. If you don't create and communicate your ownership and collaboration model correctly from the beginning, you'll end up with dozens of forks and trying to support outdated versions and are maybe worse off than if you didn't have libraries to begin with.
Vendor Documentation
- Azure DevOps Pipeline Templates
- Jenkins Pipeline Libraries
- GitHub Actions - Composite Run Steps Action
10. Pull Requests - do they trigger pipelines? Which ones?
- As I explain in this YouTube video, Pull Requests are a security backdoor. Therefore, make sure you go through all your pull request workflows and pipeline code to ensure they only run when you intend them to run.
- Are you sure production is not accidentally deployed? This is an important sanity check question. I often ask myself this too to ensure I verify my assumptions and work before moving on.
Deployment Strategies
11. What is the difference between your dev and prod environments? How does it affect your confidence to deploy to production?
- Some people are comfortable with just a dev and production environment. Other teams want a more stable "staging" environment before production. Which group do you belong to? Why?
- Most people think about source code when it comes to pre-production. What about your data? Do you have test data that is as close to production as possible? How?
12. What is your production rollout strategy?
It is very much OK to deploy manually to production, regardless of whether your organization are new to CI/CD or not. Some organizations disallow automatic deliveries (to production) for compliance reasons.
If you practice continuous delivery (and most of us are not Netflix), here are the most common options:
- Rolling Updates
- Blue/green deployments
- Canary deployments
If you choose automatic deliveries, I would challenge you further on the following questions 13-15 that also relate to deployment.
13. How do you update your database when you release a new feature to your data models?
- Do you migrate the database first and then release the new code? Or vice versa? Why?
- Is this done via your software Framework, e.g. Active Model or Entity Framework? Or are you writing SQL scripts?
- What happens if you have 2 versions of your application running against same database?
- How do you revert a database migration? Also a part of Question 15.
- Do you have model validations in your software? Do you know if existing production data is still valid? How?
14. How do you know if a deployment succeeded?
- Do you have automated end to end tests? What is your coverage percentage?
- Are you testing by hand?
- Sometimes a deployment is successful but server returns a 50x. How would you catch this? What role does monitoring play here?
15. How do you perform rollbacks?
Let's assume a security bug was deployed in your last release…
- How do you rollback code and the database if needed?
- Will your users notice? In what way?
- How will you document and version this rollback?
Think about consequences of just overwriting existing code. Can you really just do a simple git revert?
16. Do production deployments need to be approved manually?
If so, how are you achieving this? Examples include:
- Pull Requests
- Approvals and Release Gates
Security
17. Credentials and Secrets:
- Where are your credentials stored?
- Can they be exposed as plain text in any way? What happens if a developer tries to
echo $SECRETin a pipeline?
It's important to understand that giving access to run a pipeline is giving access to the secret. Once in the build job (via pipeline as code), a rogue developer could send the credential off to another location if she wanted to. Therefore it's important to discuss the role of pull requests here and how to separate credentials across environments.
18. How are you separating and storing configuration?
- What is saved in git?
- What is configured in environment variables?
- Which credentials are stored in the build server?
- Which credentials are stored in a secret management service, e.g. Azure Key Vault or HashiCorp Vault?
- How do you ensure development environments only have access to development credentials and ditto with production?
Governance
19. Are you using a single identity plane across CI/CD and the cloud?
Basically I am asking if you have the same RBAC both to the cloud API directly as well as to CI/CD starting with git? If not, you may have a back door somewhere because you would need to keep your RBACs in sync.
I have seen scenarios where developers were not allowed to access production environments from Azure Portal and Azure CLI. But if they knew how to trigger the pipelines, they could potentially take down production anyway.
20. How have you documented RBAC and ACLs?
Governance is complex, even for smaller teams. Maybe you can answer my questions today, what about next month? That's why you need to document.
See "Default permissions and access for Azure DevOps" as an example.
21. How are you ensuring only authorized developers can deploy to production?
This is an open ended question designed to test how well you understand your workflow. If you are in my customer session, I would ask you to share your screen and show access controls. I don't go over them line by line but look at:
- Branch Protection configuration, e.g. require pull requests, are force pushes allowed?
- Pull Request configuration, e.g. who can can approve, passing build requirements, etc.
22. How do you handle access to shared protected resources? (if applicable)
In larger organizations, there may be shared resources, e.g. an artifact registry that is managed outside the developer team.
- Who has write access? To which scope?
- Which resources must be shared and how do you ensure that developers have read-only access?
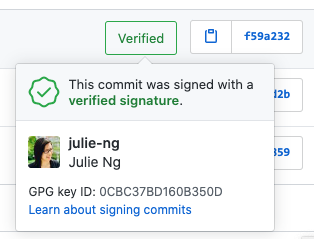
23. Are you signing your commits to verify identity? (if applicable)
Note: git only checks integrity, not authentication. The only way to verify authorship of a commit is to sign commits. Unfortunately Azure DevOps does not support this. But GitHub does.
Cost Optimization
24. Do you clean up artifacts?
Some build jobs will produce an artifact for every run. How do you clean up the ones that never make it to production and store the ones that do?
25. Do you use a different environment for development that is sized accordingly?
To save costs, your non-production environments should be configured for less performance.
Conclusion
So how did you do? After going through this list you should be able to measure your own personal confidence in your CI/CD workflow to meet your requirements. Not every question in this list may be (or should be) relevant to you. If you are unsure, do not worry. Sometimes you just need to stop for a second and document what you are currently doing.
The most important thing is to realize where you stand now, and where you want to be.
List of questions last updated 28 February 2021.
