Infrastructure as Code and Monorepos - a Pragmatic Approach
As engineers move beyond "hello world" samples, they can struggle extending the code to multiple deployment targets and creating automation pipelines. How can we structure code for re-use and automation and ensure we won't accidentally deploy to production?
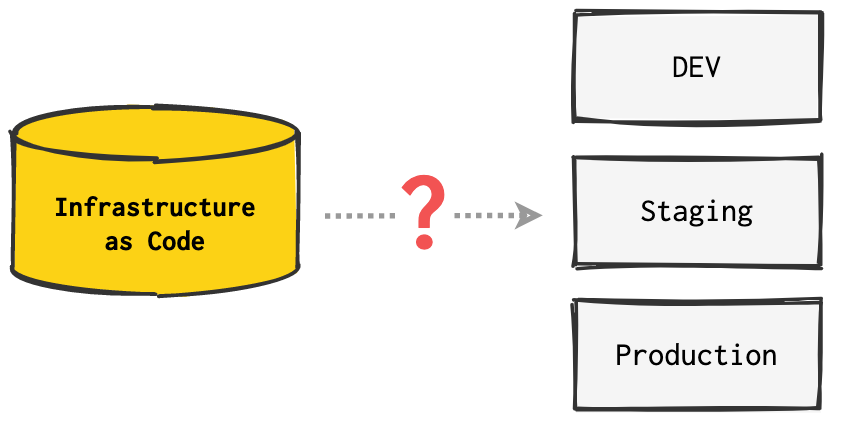
There are many ways to do this. In this article I will share one solution that uses a monorepo to deploy and manage multiple Kubernetes clusters. The source code is public, maintained and available at github.com/julie-ng/cloudkube-aks-clusters.
Disclaimer This article is a mix of best practices and walkthrough of a specific high trust use-case. Your requirements may differ.
What is a Monorepo?
In the context of cloud infrastructure automation, a monorepo approach refers to a single repository that holds both:
- deployment templates
- deployment configuration
which has the following consequences.
Advantages
- Easier to understand
- Faster to debug when configuration is next to template code
Disadvantages
- Urge to "copy & paste" code to make debugging easier than having to correlate code between two different repositories with separate git histories.
- A single repo means only 1 security boundary in git
Because you cannot use folders as a security boundary in git, anyone with write-access to the monorepo can trigger deployments, incl. to production. It is possible to introduce a soft boundary by using a combination of Pull Request workflow and protected branches. But organizations with stricter requirements to remove write-access from developers will adopt the multi-repo approach.
My Use Case
In my cloudkube-aks-clusters project, I do not need such a security boundary because it's just me and thus a high trust scenario.
Leverage Software Modules for Multiple Environments
Do not use copy and paste ever. For work in progress code, leverage git branches. If you are not experienced with creating software modules, start with a single giant file to make progress. When you can deploy the infrastructure you need (but do not wait until it's perfect), refactor into modules to follow software programming best practice and DRY your code.
Once you DRY your code, you will have an abstraction for your environment, which will include all the compute and data infrastructure for your workloads. Your abstraction will have different syntax depending on the language you choose. If you're using Pulumi and JavaScript, your abstraction may look something like this:
// example IaC Module pseudo-code
const AppEnvironment = require('custom-module')
const dev = new AppEnvironment({
name: 'dev',
postgresVersion: '14.1'
})
const prod = new AppEnvironment({
name: 'prod',
postgresVersion: '13.5'
})
I prefer Terraform, but the concepts of software modules and parameters are generic and will also apply to Azure Bicep modules and the modules ecosystem of the Pulumi language you choose, e.g. npm packages or npm modules for JavaScript.
Why are Custom Abstractions necessary?
Official modules, e.g. official Microsoft managed Terraform module for an Azure Kubernetes cluster are bare-bones by design. Many small modules allows for greatest flexibility in customizing your architecture. To get started you may use the official provider to create and deploy a resource, e.g. the Kubernetes cluster. In real life, you will eventually need to add your own specific requirements.
My Kubernetes Cluster Requirements
For example, my aks-cluster module add some security and automation resources on top of my Kubernetes cluster:
- Virtual Networks for cluster integration
- Headless security principal to be used by cluster ingress controller to fetch TLS certificates
- Headless security principal to be used in CI/CD automation
- An Azure Key Vault for Kubernetes secrets integration
- etc.
Note these resources are created per environment to follow Principle of Least Privilege, which is one of my specific requirements. Your requirements may differ.
Separate Configuration Files per Environment
Once we've created an IaC module, we can re-use the same code for multiple deployment environments. This is done using separate config files per environment. The IaC configuration only needs to know which parameters to set, for example this excerpt from my dev.cluster.tfvars:
# module config (excerpt)
name = "cloudkube-dev"
env = "dev"
hostname = "dev.cloudkube.io"
kubernetes_version = "1.20.9"
Treat your module like software and provide documentation so engineers know how to use it. At a minimum you should document required parameters and default values.
Pro Tip If you are using Terraform you can autogenerate module documentation with terraform-docs.io. See this generated README.md summary, which saves me the trouble of having to open and read multiple Terraform files. Be aware the docs are only as good as your coding.
Use Subfolders Per Environment Configuration
Now that we have re-usable IaC modules, the next challenge is to setup automation pipelines that do not unintentionally deploy to production. This is a common fear for engineers getting started with DevOps and CI/CD.
The hurdle here is to understand that while most beginner pipeline documentation focusses on branch triggers, pipelines also have path triggers and you will need both. Unlike application pipelines however, your deployment target will be determined by paths not branches.
To better understand this, let's walk through an example.
Leverage Path based Pipeline Triggers
Given the following file tree structure (with example multi-region production scenario)…
environments/
├── dev/
├── prod-northeurope/
├── prod-westeurope/
└── staging/
and given the following pipeline triggers…
# azure-pipelines/production.yaml
trigger:
branches:
- main
paths:
include:
- 'environments/prod-northeurope/*'
- 'environments/prod-westeurope/*'
I could then create pipelines that only run against production environments IF…
- a commit is pushed to the
mainbranch - a change is made to configuration files inside
prod-northeuropeandprod-westeuropesubfolders.
Work in Progress Changes
In this scenario, I can actively make changes to the Terraform modules code in the modules/ folder, but automated deployments using the triggers below will not run against production until the changes are made to the environments/prod… folders.
To better illustrate the various triggers, let's map the corresponding deployments into a table.
| Pipeline | Branch | Path | Deployment Target |
|---|---|---|---|
ci.yaml | * | * | - |
cd.yaml | dev | modules/* | DEV |
cd.yaml | dev | environments/dev/* | DEV |
cd.yaml | main | modules/* | Staging |
cd.yaml | main | environments/staging/* | Staging |
cd-production.yaml | main | environments/prod-northeurope/* | Production (North Europe) |
cd-production.yaml | main | environments/prod-westeurope/* | Production (West Europe) |
Leverage Resource Tagging and IaC Versioning
Sometimes changes may be under the hood improvements, e.g. refactoring the infrastructure as code. But you should still deploy to production to confirm that the infrastructure does not change. You can test this without changing the infrastructure by using tags. See this Azure documentation for example common tagging patterns. Resource tagging is a generic concept also offered by other cloud providers.
Using tags is straight-forward and a general good practice. Just as I tag my resources env:staging, I could also tag them iac-version:1.28 and bump the versions according to your schema. I prefer semantic versioning.
Infrastructure as Code Rollbacks
Rollbacks are a part of real life cloud engineering. And they ARE scary. But over time and with experience, it is straight-forward to rollback configuration changes with confidence.
Dev and Staging Rollbacks
Non-production rollbacks are expected to be messy because they are not versioned.
Personally, I generally only track these by the git branch heads. So if I need to undo a change, I need to change the code. Because I don't like waiting minutes for CI builds, I tend to apply Terraform changes locally and check in the code after I have the result I want. So when the pipeline runs against a remote backend, it won't find any configuration changes and not execute terraform apply.
The trade-off here is the risk of the "it works on my machine" effect. In the cloudkube-aks-clusters repo, I'm the only contributing engineer and thus the risk is low. Your mileage will vary.
Production Rollbacks
The key here is discipline when using git. In general for both application and infrastructure workloads, I tend to track production code with with both
productionormainbranch heads, i.e. tips- git tags in semantic versioning format. See example CHANGELOG.md created with standard-version from this cloudkube-aks-clusters repo.
Using tags, I have a clearer overview of intended deloyments. In the simplest scenario, if I am at v0.3.0 but want to rollback to v0.2.1, I would return the code to that previous point (preferably without a force push) and re-deploy.
Deployments outside of Pipeline Runs
Most engineers understand that for example the v0.3.0 deployment might be numbered deployment #86 and the rollback is deployment #87. But there can also be a deployment gap, for example:
| Deployment # | Trigger | Details |
|---|---|---|
| 86 | git push | Pipeline Deploy of v0.3.0 |
| 87 | Nightly Scheduled Run | Resolve configuration drift that someone did in Cloud Provider UI |
| 88 | Manual or git push | Pipeline Deploy or Manual Rollback to v0.2.1 |
In this example an engineer intentionally triggers deployment #86 and #88. But the deployment #87 runs in between and may be triggered outside the normal engineer workflow. It can be en engineer who configured their own scheduled nightly runs. It can also be change that is enforced centrally, for example if an organization uses Azure policy to strictly enforce governance of their cloud real estate.
To have predictable and reliable infrastructure, you need to be aware of all the ways deployments can happen, including the ones outside of your control.
When should you not use a Monorepo?
Starting with a monorepo is the quickest way to deployment. It's simple but also very versatile for the experienced engineer.
So when should you not use a monorepo? That will be a future article ;-) Follow me on Twitter and YouTube to be notified when it gets published.
P.S. Props to anyone who went through the julie-ng/cloudkube-aks-clusters code and noticed it does not have any pipeilnes. That's another way to approach security - remove automation altogether ;-)
In all seriousness, if you're looking for infrastructure as code pipeilnes, checkout the azure/devops-governance repo, which follows a very similar pipeine structure to the one described above. That project includes pipelines because they deploy to a Visual Studio Enterprise subscription on my personal Azure AD tenant. The Kubernetes clusters project described in this article is deployed to a Microsoft internal Azure subscription. So there are no automation pipeilnes in this public repository to be better safe than sorry.
